Attention
概要
入力として埋め込みベクトルを受け取り文脈を考慮した新たな埋め込みベクトルを出力します。
シェイプ
- $B$:バッチ数
- $C$:コンテキスト長
- $E$:埋め込みベクトル次元数
- $D$:クエリ、キー次元数
[!NOTE]
(通常)バリューの次元数は埋め込みベクトルと同じ $E$ です。
ただしバリューを埋め込みベクトルとは呼ばずバリューベクトルと呼ぶのが一般的です。
[!NOTE]
3 階テンソルのシェイプ: $(B, C, D)$
※ Attention の文脈では B はバッチを想定。PyTorch は 3 階テンソル( 3 次元配列)の最初の次元がバッチ次元を表します。
\[(B, C, D) \cdot (B, D, C) = (B, C, C) \quad \text{※ 最初の次元は独立。 2, 3 次元目は通常の行列積}\]
行列積ではバッチ次元は独立して計算されます。
クエリ、キー、バリュー
埋め込みベクトル $x$ と重み行列 $W_q$ 、 $W_k$ 、$W_v$ からクエリ $Q$ 、 キー $K$ 、バリュー $V$ を算出します。
\[\begin{aligned} \underbrace{Q}_{(C, D)} = \underbrace{x}_{(C, E)} \cdot \underbrace{W_q}_{(E, D)} \\ \underbrace{K}_{(C, D)} = \underbrace{x}_{(C, E)} \cdot \underbrace{W_k}_{(E, D)} \\ \underbrace{V}_{(C, E)} = \underbrace{x}_{(C, E)} \cdot \underbrace{W_v}_{(E, E)} \end{aligned}\]Step 1. 類似度を算出
キーとクエリの行列積(類似度)$Q \cdot K^\top (C, C)$ を求めます。
\[\begin{aligned} Q \cdot K^\top \end{aligned} \quad \text{※ シェイプ}\ (C, C)\][!NOTE]
2 つのベクトルの内積は各ベクトルの絶対値(大きさ)が大きく同じ向きの場合に大きくなります。
Step 2. Attention 重み( Attention マップ)を算出
Softmax 関数で類似度 を確率 $(C, C)$ に正規化します。
Softmax の入力 $(Q \cdot K\top)$ のシェイプは $(C, C)$ なので出力される確率行列のシェイプも $(C, C)$ です。
確率化した類似度を Attention 重み(または Attention マップ)と呼びます。
[!NOTE]
Attention マップは各トークンが他のトークンの情報をどの程度参照するかを示す行列です。(p81)
※ マスクを考慮していません。
Step 3. 文脈を考慮した埋め込みベクトル $Attention(Q, K, V)$ を算出
文脈を考慮した埋め込みベクトル $Attention(Q, K, V)$ を算出します。
今の段階で求められる $Attention(Q, K, V)$ はマスクなし Attention です。
[!NOTE]
スケーリング( $\sqrt{D}$ ):
$Q \cdot K^\top$ を $\sqrt{D}$ で除算して飽和を防ぎます。
$\sqrt{D}$ で除算することで $Q \cdot K^\top$ の分散を 1 に近づけることができます。一般的に飽和とは入力を変化させても出力が変化しない状態を指します。
つまり $Q \cdot K^\top$ が変化しても $Attention(Q, K, V)$ に変化が起きなくなります
マスク
現状は $Softmax(Q \cdot K^\top) \cdot V$ はすべての情報を考慮して算出されています。
つまり未来の埋め込みベクトルを考慮しています。
未来の情報を考慮しない(確率 0 )ようにマスクを設定します。
具体的には次のステップでマスクを設定します。
- $Q \cdot K^\top$ の未来の情報を $-\infty$ に設定
- $Softmax(\frac{Q \cdot K^\top}{\sqrt{D}})$ は未来の確率が 0 の下三角行列
Python でマスクを実装
```python import torch import torch.nn as nn import torch.nn.functional as F class Attention(nn.Module): def __init__(self, embed_dim, key_dim): super().__init__() # Q, K, Vの変換行列 self.W_q = nn.Linear(embed_dim, key_dim, bias=False) self.W_k = nn.Linear(embed_dim, key_dim, bias=False) self.W_v = nn.Linear(embed_dim, embed_dim, bias=False) self.key_dim = key_dim def forward(self, x): # x: (B, C, E) Q = self.W_q(x) # Q: (B, C, D) K = self.W_k(x) # K: (B, C, D) V = self.W_v(x) # V: (B, C, E) # Attentionマップの計算 # Kの最後から2番目の次元と、最後の次元を入れ替える K_t = K.transpose(-2, -1) # (B, D, C) scores = torch.matmul(Q, K_t) # (B, C, C) scores = scores / (self.key_dim ** 0.5) # マスクの適用 B, C, E = x.shape # PyTorch は異なるデバイス上のテンソル同士は演算できません。 # devices=scores.device で scores デバイス( CPU / GPU )と同じデバイスを指定して mask を作成します mask = torch.tril(torch.ones(C, C, device=scores.device)) scores = scores.masked_fill(mask == 0, float('-inf')) weights = F.softmax(scores, dim=-1) output = torch.matmul(weights, V) # (B, C, E) return output attention = Attention(embed_dim=256, key_dim=64) x = torch.randn(2, 5, 256) # (batch_size=2, context_len=5, embed_dim=256) y = attention(x) print("入力形状:", x.shape) print("出力形状:", y.shape) ```行列分解による低ランク近似
$x:(5, 100)$ の $x \cdot W_v$ を考えます。
バリューの重み行列 $W_v$ のシェイプは $(100, 100)$ で 1,000,000 個のパラメータが必要になります。
$W_v$ を分解します。
行列積の演算ができるように分解します。
行列 $x$ に対して $W_v$ を適切に分解した $W_{v1}, W_{v2}$ を使って $X \cdot W_{v1} \cdot W_{v2}$ を計算できます。
パラメータ数は 1,000,000 から 2,000 に 80 % 削減されます。
$W_v$ と $W_{v1} \cdot W_{v2}$ は $=$ (イコール) ではなく $\approx$(近似)です。
$X \cdot W_{v1} \cdot W_{v2}$ は $X \cdot W_v$ の近似になります。
出力変換行列(行列分解によるあらたな解釈)
$W_{v1}$ を $W_v$ 、$W_{v2}$ を $W_o$ とします。
バリュー $V$ は $V = x \cdot W_v \cdot W_o$ で表せます。
※ 多くの場合、$W_v$ のシェイプはクエリやキーと同じ $(C, D)$ にします(よって $W_o$ のシェイプは $(D, E)$ です)。
$Attention(Q, K, V)$ は以下のように表せます。
\[Attention(Q, K, V) = (Softmax(\frac{Q \cdot K^\top}{\sqrt{D}}) \cdot V) \cdot W_o\]多くの論文や実装はでバリュー $V = x \cdot W_v$ と出力変換行列( $W_o$ )を分けています。
マルチヘッド Attention
マルチヘッド Attention は複数の Atention を並列で動作させます。
各ヘッド( Head )は独立した重みを持ちます。
i 番目のヘッド:
\[\begin{aligned} Q^i = x \cdot W^i_q \\ K^i = x \cdot W^i_k \\ V^i = x \cdot W^i_K \\ \underbrace{head_i}_{(C, E)} = (Softmax(mask(\frac{Q{^i}\cdot (K^i)^\top}{\sqrt{D}}) \cdot V^i) \cdot W^i_o \end{aligned}\]マルチヘッド Attention:
\[\begin{aligned} \underbrace{MultiHead(x)}_{(C, E)} = \sum_{i=1}^{h}(Softmax(mask(\frac{Q{^i}\cdot (K^i)^\top}{\sqrt{D}}) \cdot V^i) \cdot W^i_o \end{aligned}\]効率化
マルチヘッドの効率化を図ります。
\[\begin{aligned} \underbrace{Ri}_{(C, D)} = (Softmax(mask(\frac{Q{^i}\cdot (K^i)^\top}{\sqrt{D}}) \cdot V^i) \\ \\ \underbrace{MultiHead(x)}_{(C, E)} = \underbrace{\begin{bmatrix}R^1, R^2, ...... , R^h\end{bmatrix}}_{(C, H*D)} \cdot \underbrace{\begin{bmatrix}W^1_o \\ W^2_o \\ ...\\ W^h_o\end{bmatrix}}_{(H*D, E)} \end{aligned}\]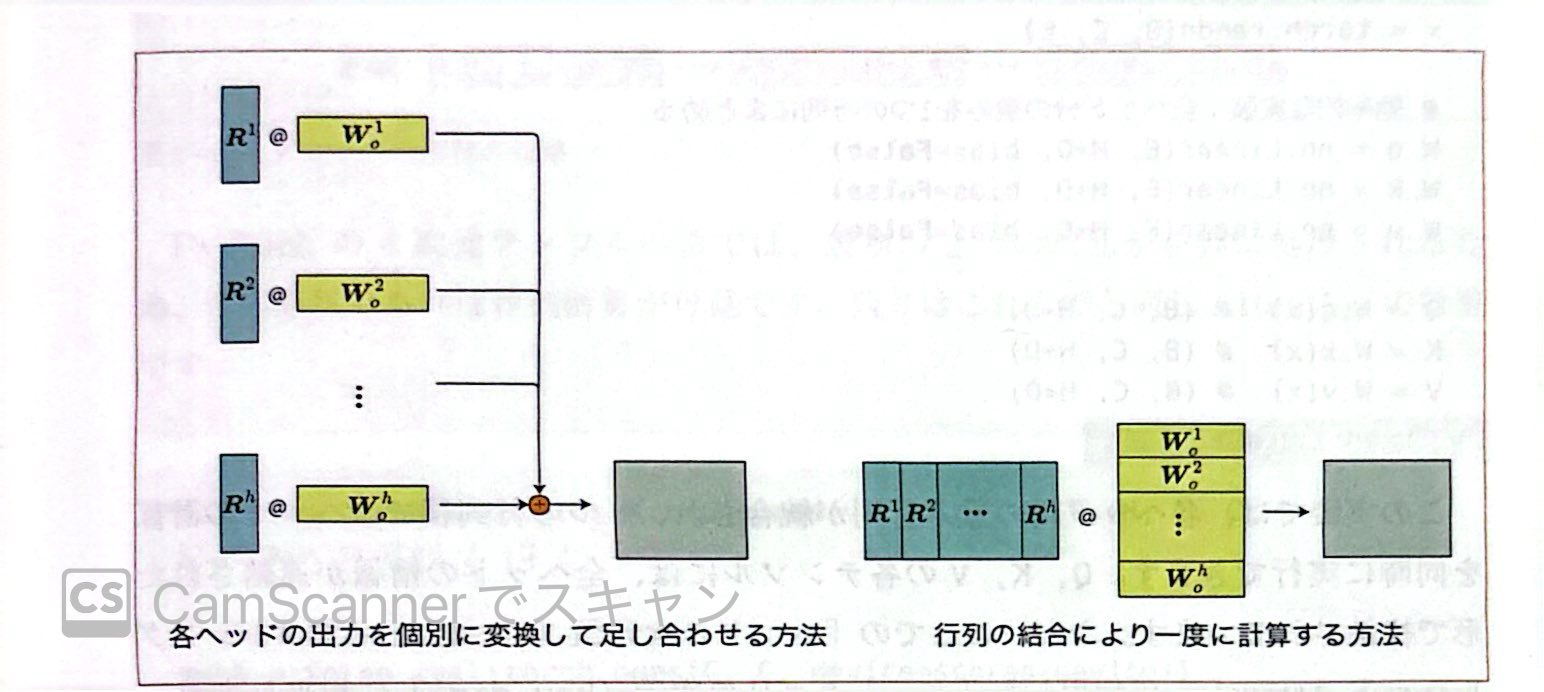
まとめ
(分かりやすさを優先して)シングルヘッド Attention についてまとめます。
入力としてシェイプ $(C, E)$ の埋め込みベクトル $x$ を受け取り文脈を考慮したシェイプ $(C, E)$ の新たな埋め込みベクトル $Attention(Q, K, V)$ を出力します。
\[\begin{aligned} \underbrace{Attention(Q, K, V)}_{(C, E)} = (Softmax(\frac{\overbrace{Q}^{(C, D)} \cdot \overbrace{K^\top}^{(D, C)}}{\sqrt{D}}) \cdot \underbrace{V}_{(C, D)}) \cdot \underbrace{W_o}_{(D, E)} \\ \text{※ } W_v(E, E)\ を\ W_v(E, D),\ W_o(D, E)\ \text{に分割} \end{aligned}\]埋め込みベクトル $Attention(Q, K, V)$ は FFN に渡されて最終的に各位置の確率がその位置の次にくるトークンの予測を表す C 個の確率分布( $\text{シェイプ:} (C, V) \ \text{※ V は語彙サイズ}$)になります。
Transformer
LLM の流れは C 個のトークン ID 列を入力すると、入力と同じ C 個の確率分布が得られます。 C の各行の確率分布は、その位置の次に来るトークンの予想を表します。
全体像
![]()
- Embed:トークン ID 列は、 Embed (埋め込み)によって埋め込みベクトルに変換されます
- Attention と FFN ( Feed-Forward Network )による変換が繰り返し実行されます
- Attention と FFN を合わせて Transformer ブロックと呼びます
- Linear (線形変換): 各トークンの埋め込みベクトルを語彙サイズと同じ次元数に変換します(出力をスコアと呼びます)
- Softmax 関数: スコアから次に出現するトークンの確率分布を生成します
Transformer ブロック( Attention と FFN )を通過するデータは、一貫して同じ形状を維持します。
例では $(C, E)$ になります。
この一貫性により Transforer ブロックによる複数回の処理が可能となります。
Embed
Embeding レイヤー(埋め込み層)は、トークン ID(入力)に対応する重み行列に格納された分散表現ベクトルを出力します。
重み行列
- 重み行列のシェイプ( $W$ ): (語彙数 $V$, 埋め込み次元 $D$)
- 各行がトークンの分散表現ベクトルに対応
順伝播
- 入力:トークン ID(整数)、例えば id = 42
- 出力:
W[42]、つまり 42 行目のベクトル(分散表現ベクトルの次元数 $D$ ) - 実装上は(入力トークンの) one-hot ベクトルとの行列積と数学的に等価ですが、実際は単なるテーブルルックアップ(行の抜き出し)として実装されます
学習との関係
この重み行列 $W$ は学習によって更新されます。
結果として、意味的・文法的に近いトークンが空間上で近くなるよう分散表現が形成されます。
補足:バッチ処理の場合
入力が (バッチサイズ, コンテキスト長) なら出力は (バッチサイズ, コンテキスト長, $D$ ) のテンソルになります。
Attention と FFN
Attention と FFN を合わせて Transformer ブロックと呼びます。
Transformer ブロックを通過するテンソルの形状は一貫しています( $(C, E)$ )。
そのため Transformer ブロックを複数回適用することができます。
詳細は Attention を参照。
Linear と Softmax
形状が $(C, E)$ のテンソルは、線形変換によって $(C, V)$ の形状に変換されます。
$V$ はトークンの語彙サイズを表します。
Softmax 関数によって C 個の確確分布が得られます。 各位置の確率分布は、その位置の次に来るトークンの予想を表します。
C = 5 ( This is a pen .)
V = 1000
0 1 999
This [0.001, 0.021, ......, 0.002]
is [0.020, 0.001, ......, 0.060]
a [0.020, 0.001, ......, 0.060]
pen [0.100, 0.001, ......, 0.001]
. [0.034, 0.021, ......, 0.071]
This の確率分布 [0.001, 0.021, ......, 0.002] は This の次にくるトークンの確率分布を表します
is の確率分布 [0.020, 0.001, ......, 0.060] は This is の次にくるトークンの確率を表します
a の確率分布 [0.020, 0.001, ......, 0.060] は This is a の次にくるトークンの確率分布を表す
pen の確率分布 [0.100, 0.001, ......, 0.001] は This is a pen の次にくるトークンの確率分布を表します
. の確率分布 [0.034, 0.021, ......, 0.071] は This is a pen . の次にくるトークンの確率分布を表します
補足
アイデア
3 階テンソルの 1 次元目は独立して扱えます。
埋め込みベクトルバッチ $(B, C, E)$ についてまず $(C, E)$ 考えます。
- B:バッチサイズ(例:2 )
- C:コンテキスト長(例:2 )
- E:埋め込みベクトルの次元数(例:3 )
- H:ヘッド数(例:2 )
- D:クエリ・キー・バリューの次元数(例:2 )
- $W_q^h, W_k^h$ のシェイプ: $(E, D)$
- $W_q, W_k$ のシェイプ: $(E, H*D)$
- $W_v^h$ のシェイプ: $(C, D)$
- $W_v$ のシェイプ: $(C, H*D)$
- $W_o^h$ のシェイプ: $(C, H*E)$