LSTM
LSTM は 隠れ状態 $h$ に加えて記憶セル $c$ を導入することで RNN の勾配消失問題を解決します。
記法
本ドキュメントは以下の記法で統一しています。
| 記号 | 意味 |
|---|---|
| $\cdot$ | 行列のドット積(行列積) |
| $\odot$ | 要素積(アダマール積、element-wise product) |
勾配消失問題
勾配消失は 逆伝播 で問題になります( 順伝播 では問題になりません)。
中間変数 $$1$ を定義(活性化関数への入力):
\[a = h_{t-1} \cdot W_h + x_t \cdot W_x + b\] \[h_t = \tanh(a)\]逆伝播と勾配消失のメカニズム
$h_{t-1}$ の勾配:$\frac{\partial L}{\partial h_{t-1}}$
\[\frac{\partial L}{\partial h_{t-1}} = \frac{\partial L}{\partial h_t} \odot \underbrace{(1 - h_t^2)}_{\tanh の微分} \cdot W_h^\top\]$h_{t-2}$ の勾配:$\frac{\partial L}{\partial H_{t-2}}$
\[\frac{\partial L}{\partial h_{t-2}} = \lbrace \frac{\partial L}{\partial h_t} \odot (1 - h_t^2) \cdot W_h^\top \rbrace \odot (1-h_{t-2}^2) \cdot W_h^\top\][!NOTE]
️ $W_h^\top$ の $\top$ は転置を表します。
t ステップ遡ると $W_h^\top$ の積が t 回繰り返される:
\[\frac{\partial L}{\partial h_1} \propto \frac{\partial L}{\partial h_t} \cdot \underbrace{(W_h)^\top \cdot (W_h)^\top \cdot ...... \cdot (W_h)^\top }_{t 回 の行列積}\][!NOTE]
$\propto$ は「比例する」の意味です。他の係数を省略して本質的な部分だけ示しています。
勾配消失の 2 つの要因
| 要因 | 値の範囲 | 問題 |
|---|---|---|
| $\tanh$ の微分は $(1 - h_t^2)$ 。tanh の値域は 0 < y < 1 なので $1-h_t^\top$ は常に [0, 1] | 常に $[0, 1]$ | 掛けるたびに小さくなる |
| $W_h$ のスペクトル半径 $\rho < 1$ | 固有値の絶対値 < 1 | t 乗で 0 に収束 |
固有値
定義
正方行列 $$1$ に対して、ゼロでないベクトル $v$ とスカラー $λ$ が以下の関係を満たすとき $λ$ を $$1$ の固有値、$v$ を $λ$ に対応する固有ベクトルといいます。
\[A \mathbf{v} = \lambda \mathbf{v}\]- 固有値は
正方行列全体に対して定義されます - $n \times n$ 行列には n 個の固有値が存在します(複素数を含む)
| 記号 | 意味 |
|---|---|
| $\mathbf{v}$ | 固有ベクトル(掛けても方向が変わらない特別なベクトル) |
| $\lambda$ | 固有値(その方向に何倍伸び縮みするか) |
具体例
\[A = \begin{pmatrix} 2 & 0 \\ 0 & 3 \end{pmatrix}\]- $\mathbf{v} = \begin{pmatrix} 1 \ 0 \end{pmatrix}$ → 固有値 $\lambda = 2$(2倍に伸びる)
- $\mathbf{v} = \begin{pmatrix} 0 \ 1 \end{pmatrix}$ → 固有値 $\lambda = 3$(3倍に伸びる)
固有値と勾配消失・爆発の関係
| $\rho(W_h) = \max_i | \lambda_i | $(最大固有値の絶対値)をスペクトル半径と呼びます。 |
| 条件 | $W_h^T$ の挙動 | 結果 |
|---|---|---|
| $\rho < 1$(全固有値の絶対値 < 1) | $\to 0$ | 勾配消失 |
| $\rho = 1$ | 安定 | 安定 |
| $\rho > 1$(ある固有値の絶対値 > 1) | $\to \infty$ | 勾配爆発 |
[!NOTE]
消失と爆発が同時に発生刷る場合もあります(ある成分は 0 へ、別の成分は $\infty$ へ)
LSTM による解決策
RSS で導入した(勾配消失問題を持つ)隠れ状態 $h_t$ に加えて記憶セル $c_t$ を導入します。 以下に $c_t$ について勾配消失の影響を受けない理由を説明します。
セル状態 $c_t$ の順伝播
\[c_t = \underbrace{f_t \odot c_{t-1}}_{\text{過去を保持}} + \underbrace{g_t \odot i_t}_{\text{新情報を追加}}\]セル状態 $c_t$ の逆伝播
$c_t$ を $c_{t-1}$ で微分すると:
\[\frac{\partial c_t}{\partial c_{t-1}} = f_t\]- $f_t \odot c_{t-1}$ を $c_{t-1}$ で微分 : $f_t$ が残る
- $i_t \odot \tilde{c}t$ を $c{t-1}$ で微分 : $c_{t-1}$ を含まないので 0 になる(加算項は消える)
t 時刻について展開すると:
\[\frac{\partial L}{\partial c_0} = \frac{\partial L}{\partial c_T} \cdot \prod_{k=1}^{T} f_k\]単純 RNN との比較
| 単純 RNN | LSTM | |
|---|---|---|
| 逆伝播で掛かるもの | 固定の $W_h$(変えられない) | 時刻 t ごとに異なる $f_t$(学習で制御できる) |
| 値の範囲 | 固有値に依存(正確にはスペクトル半径) | sigmoid なので $(0, 1)$ |
| 制御 | 困難 | $f_t \approx 1$ に学習できる |
| 長期依存 | 学習困難 | 学習できる |
LSTM が勾配消失に強い理由
理由 1. $f_t$ が時刻ごとに独立(異なる値)
- 単純 RNN は 同じ $W_h$ の t 乗:固有値(スペクトル半径)に支配される
- LSTM は 毎時刻異なる $f_t$ の積:固有値問題が起きない
理由 2. $f_t$ を学習で制御できる
$f_t$ は $\text{sigmoid}$ なので値の範囲は $(0, 1)$ です。
[!NOTE]
- $f_t \approx 1$ に学習:勾配がほぼそのまま過去へ流れます(長期記憶を保持)
- $f_t \approx 0$ に学習:意図的に過去の情報を遮断できます(忘却)
[!NOTE] この仕組みを定常誤差カルーセル(CEC: Constant Error Carousel)と呼ぶ
$f_t$ を制御刷る方法う
\[y = \sigma(x) = \frac{1}{1 + \exp(-x)}\]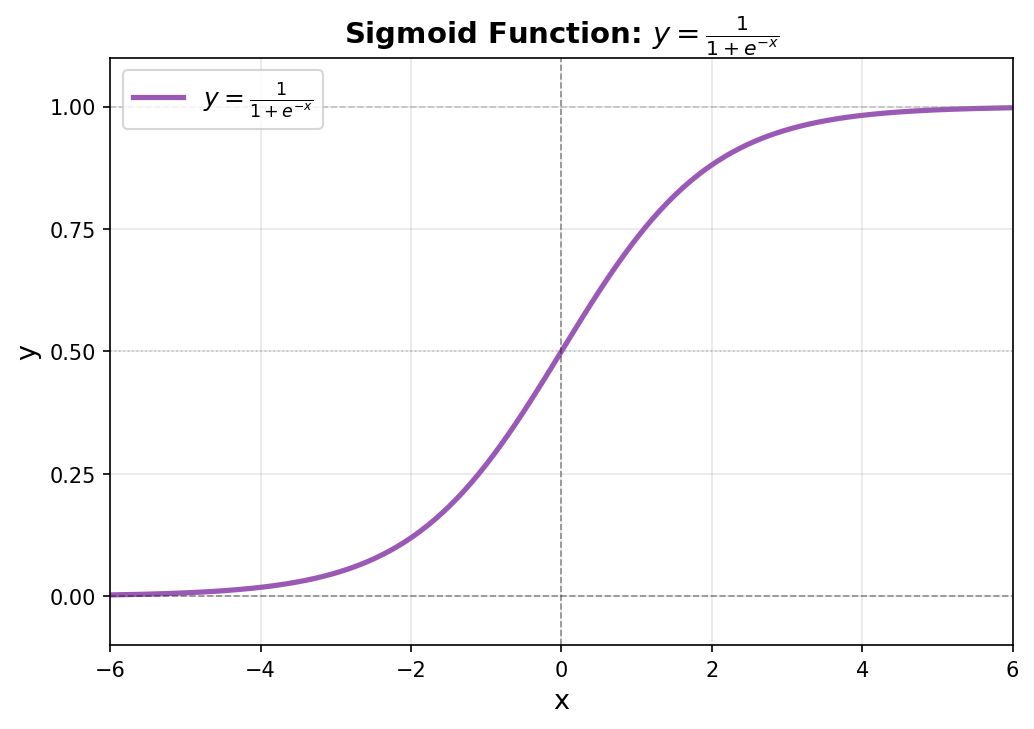
sigmoid 関数( $\sigma$ )に渡す $a_t^f$ を大きくすれば $f_t$ は 1 に近づきます。
もっとも簡単な方法はバイアス $b$ を大きくすることです。
加算構造が勾配のハイウェイとして機能する理由
$c_t$ の更新式を 2 項の加算として見ると:
\[c_t = \underbrace{f_t \odot c_{t-1}}_{\text{項A}} + \underbrace{g_t \odot i_t}_{\text{項B}}\]逆伝播で上流から勾配 $\frac{\partial L}{\partial c_t}$ が来たとき、加算ノードはそれをそのまま 1 倍で項 A・項 B の両方に流します。
\[\frac{\partial L}{\partial (f_t \odot c_{t-1})} = \frac{\partial L}{\partial c_t} \times 1 = \frac{\partial L}{\partial c_t}\]項 A への勾配は減衰しません。これが「加算がハイウェイとして機能する」という意味です。
[!NOTE]
項 A の内部 $f_t \odot c_{t-1}$ はさらに乗算なので、$c_{t-1}$ まで遡ると $f_t$ が掛かります。 最終的な勾配消失の制御は前半の $f_t$ の議論(理由 1・2 )に帰着します。 加算構造は「勾配が通る経路を確保する」補強であり、両者が合わさって初めて完結します。
LSTM 詳細
LSTM とは短期記憶( short term memory )を長い( long )時間継続すること意味します。 具体的には勾配消失を受けにくい(制御できる)記憶セル $c_t$ を導入します。
順伝播
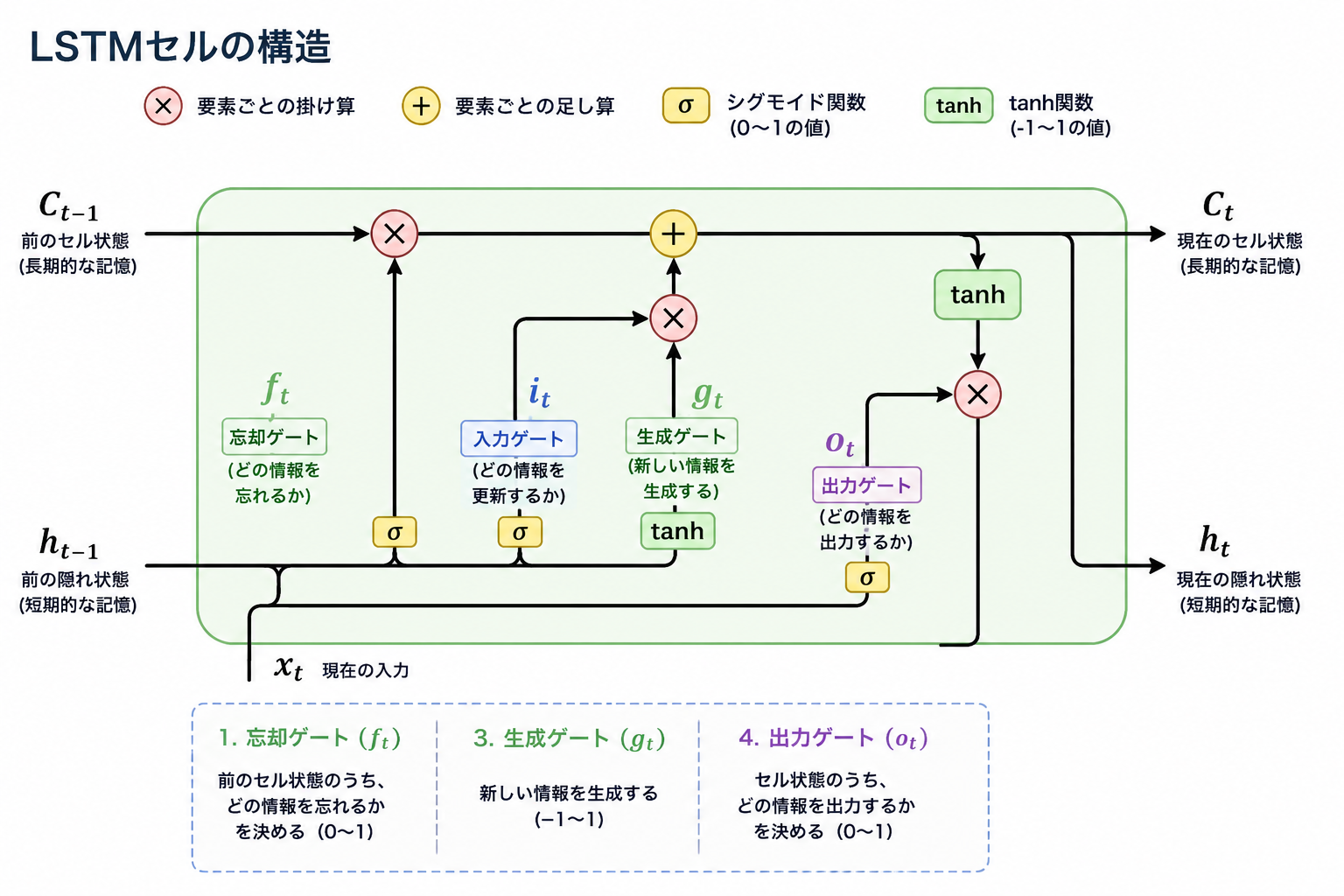
LSTM は状態を保持する隠れ状態 $h_t$ に加えて記憶を表すセル状態 $c_t$ を持ちます。
$c_t$, $h_t$ の順伝播は以下のとおりです。
- $f_t \odot c_{t-1}$:過去の記憶を $f_t$ の割合で残す
- $g_t \odot i$:新しい情報 $g_t$ を $i_t$ の割合で追加する
- $\tanh(c_t)$:セル状態を $(-1, 1)$ に正規化
- $o \odot$:出力ゲートで「どれだけ外に出すか」を制御
- $h_t$, $c_t$ は ゲート $f_t, i_t, g_t, o_t$ の影響を受ける
- $f, i, o$ は情報を反映する割合を表すので活性化関数は sigmoid 関数を使用するので各要素が 0 < y < 1 の $(N, H)$ 次元の配列
- $g$ は追加する情報の大きさを表すので活性化関数として tanh 関数を使用するので各要素が -1 < y < 1 の $(N, H)$ 次元の配列
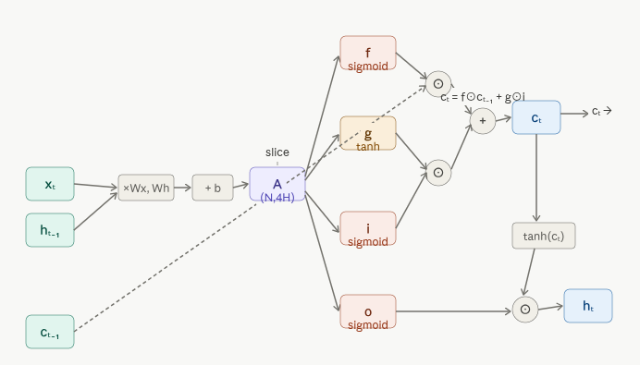
効率的に計算するため $f, i, g, o$ の Affine 変換をまとめて計算できるようにします。
\[\begin{aligned} A = h_{t-1} \cdot W_h + x_t \cdot W_x + b \\ \\ W_x^f \neq W_x^i \neq W_x^g \neq W_x^o \\ W_h^f \neq W_h^i \neq W_h^g \neq W_h^o \end{aligned}\]コード
以下 forget を $f$ 、input を $i$、 generate を $g$ 、output を $o$ で表します。
- バッチサイズ:N
- 入力の分散表現の次元:D
- $x_t$ の次元:$(N, D)$
- $W_x$ の次元: $(D, 4H)$
- $W_x^f \neq W_x^i \neq W_x^g \neq W_x^o$ をまとめて $W_x$ と表記(各重み行列は $(D, H)$ )
- 隠れ状態の分散表現の次元:H
- $h_t$ の次元: $(N, H)$
- $W_h$ の次元: $(H, 4H)$
- $W_h^f \neq W_h^i \neq W_h^g \neq W_h^o$ をまとめて$ $W_h$ と表記(各重み行列は $(H, H)$ )
- forget, input, output ゲートおよび generate をまとめて考える場合
- セル状態(記憶)の次元: H
- $c_t$ の次元; $(N, H)$
- $b$ の次元:$(1, 4H)$
import numpy as np
# h_t-1(h_prev), c_t-1(c_prev) は所与とする
input_size = 3
H = hidden_size = 4
bach_size = 10
# 作成 = (4, 4 * 4) 版
W_h = np.random.randn(hidden_size, 4 * hidden_size) # shape: (4, 16)
# W_x の同様に求める
W_x = np.random.randn(input_size, 4 * hidden_size) # shape: (3, 16)
# Affine 部分( h_prev は h_{t-1} で (3, 4) のミニバッチ
# x @ Wx (10, 16), h_prev @ Wh (10, 16) なので加算可能
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
# 活性化関数に適用
# sigmoid は定義済みとする
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
# c_t, h_t を取得
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
# 補足:取り出し(列方向)
# W_h_f = W_h[:, 0 * hidden_size : 1 * hidden_size] # forget gate
# W_h_i = W_h[:, 1 * hidden_size : 2 * hidden_size] # input gate
# W_h_g = W_h[:, 2 * hidden_size : 3 * hidden_size] # cell gate
# W_h_o = W_h[:, 3 * hidden_size : 4 * hidden_size] # output gate
$$1$ を使って f, i, g, o を求める Python コードです。
| スライス | 取り出す列 | shape |
|---|---|---|
A[:, :H] |
$0 \sim H$ | $(N, H)$ |
A[:, H:2*H] |
$H \sim 2H$ | $(N, H)$ |
A[:, 2*H:3*H] |
$2H \sim 3H$ | $(N, H)$ |
A[:, 3*H:] |
$3H \sim 4H$ | $(N, H)$ |
LSTM と RNN の比較
入力と隠れ状態
| 内容 | RNN | LSTM |
|---|---|---|
| 引数 | x, h_prev |
x, h_prev, c_prev |
| 返り値 | h_next |
h_next, c_next |
| 記憶 | $h$(隠れ状態)のみ | $h$(隠れ状態)+ $c$(セル状態) |
c( cell state )は LSTM が新たに持つ長期記憶。
重みの shape
RNN との比較:
| パラメータ | RNN | LSTM |
|---|---|---|
| $W_x$ | $(D, H)$ | $(D, 4H)$ |
| $W_h$ | $(H, H)$ | $(H, 4H)$ |
| $b$ | $(1, H)$ | $(1, 4H)$ |
4つのゲート分をまとめて1つの行列に格納しています。
4つのゲート
| 記号 | 名前 | 活性化関数 | 役割 |
|---|---|---|---|
| $f$ | forget gate | sigmoid | 過去の記憶 $c_{t-1}$ をどれだけ忘れるか |
| $g$ | cell gate | tanh | セル状態に加える新しい情報 |
| $i$ | input gate | sigmoid | $g$ をどれだけセル状態に反映するか |
| $o$ | output gate | sigmoid | セル状態 $c_t$ からどれだけ出力するか |
なぜ sigmoid と tanh を使い分けるか
| 関数 | 値域 | 用途 |
|---|---|---|
| sigmoid | $(0, 1)$ | 割合・比率(どれだけ通すか)→ ゲート制御 |
| tanh | $(-1, 1)$ | 情報量(値の大きさ・方向)→ 新情報・出力 |
$f$、$i$、$o$ は「0 〜 1 の割合」として機能するので sigmoid。
$g$ は新しい情報そのものなので符号を含む tanh。
逆伝播
$\frac{\partial L}{\partial W_h^f}$
逆伝播の例として重み行列 $W_h^f$ の勾配 $\frac{\partial L}{\partial W_h^f}$ を考えます。
連鎖律は $\frac{\partial L}{\partial c_t} \odot \frac{\partial c_t}{\partial f} \odot \frac{\partial f}{\partial A^f} \odot \frac{\partial A^f}{\partial W_h^f}$ になります( 経路: $L \rightarrow c_t \rightarrow f \rightarrow A^f \rightarrow W_h^f$ )。
$\frac{\partial L}{\partial c_t}$
\[\frac{\partial L}{\partial c_t} = dc\_next + dh\_next \odot o \odot (1−\tanh^2(c_t)) = ds\]$c_t$ の逆伝播は t + 1 が返す dc_next と t 自身ので $dh_next \odot o \odot (1−\tanh^2(c_t))$ の和になります。
| 勾配 | 意味 | ゼロから作る Deep Learning 2 のコード変数 |
|---|---|---|
| $\frac{\partial L}{\partial h_t}$ | 時刻 t + 1 の LSTM が $h_t$ に対して求めた勾配 | $dh_next |
| $\frac{\partial L}{\partial c_t}$ の一部 | 時刻 t + 1 の LSTM が $c_t$ に対して求めた勾配 の一部(経路 1) | dc_next |
| $\frac{\partial L}{\partial c_t}$ とイコール | $c_t$ に対する完全な勾配(経路 1 は t + 1 から、経路 2 は t 自身で計算) | ds |
$c_t$ の経路:
- 経路 1 ( $c_t \rightarrow c_{t+1}$ ):t + 1 のステップが dc_next として返してくれる
- 経路 2 ($c_t \rightarrow h_t$ ):ステップ T で計算する $dh_next \odot o \odot (1−tanh^2(c_t))$
$\frac{\partial c_t}{\partial f} = c_{t-1}$
$\frac{\partial c_t}{\partial f}$ を求めるために $f \odot c_{t−1} + g \odot i$ を $f$ で微分します。
\[\frac{\partial c_t}{\partial f} = c_{t-1}\]$\frac{\partial f}{\partial A^f}$, $\frac{\partial i}{\partial A^i}$, $\frac{\partial g}{\partial A^g}$, $\frac{\partial o}{\partial A^o}$
\[A = h_{t-1} \cdot W_h + x_t \cdot W_x + b\] \[A^f = h_{t-1} \cdot W_h^f + x_t \cdot W_x^f + b \\ A^i = h_{t-1} \cdot W_h^i + x_t \cdot W_x^i + b \\ A^g = h_{t-1} \cdot W_h^g + x_t \cdot W_x^g + b \\ A^o = h_{t-1} \cdot W_h^o + x_t \cdot W_x^o + b\] \[f = \sigma( A^f) \\ i = \sigma( A^i) \\ g = \tanh( A^g) \\ o = \sigma( A^o)\]上記より:
\[\frac{\partial f}{\partial A^f} = \frac{\partial \sigma}{\partial A^f} = f(1-f) \\ \frac{\partial i}{\partial A^i} = \frac{\partial \sigma}{\partial A^i} = i(1-i) \\ \frac{\partial g}{\partial A^g} = \frac{\partial \tanh}{\partial A^g} = (1-g^2) \\ \frac{\partial o}{\partial A^o} = \frac{\partial \sigma}{\partial A^o} = o(1-o)\]$\frac{\partial A^f}{\partial W_h^f}$, $\frac{\partial A^i}{\partial W_h^i}$, $\frac{\partial A^g}{\partial W_h^g}$, $\frac{\partial A^o}{\partial W_h^o}$
f を例にとると $A^f = h_{t-1} \cdot W_h^f + x_t \cdot W_x^f + b$ を $W_h^f$ で偏微分して $\frac{\partial A^f}{\partial W_h^f} = h_{t-1}$ を求めます。
同様に $A^i$, $A^g$,$A^o$ の偏微分 $\frac{\partial A^i}{\partial W_h^i}$, $\frac{\partial A^g}{\partial W_h^g}$, $\frac{\partial A^o}{\partial W_h^o}$ を求めます。
[!NOTE]
実際の計算は以下のようになります。$\frac{\partial L}{\partial W_h^f} = h_{t-1}^\top \cdot \frac{\partial L}{\partial A^f}$
$h_{t-1}^\top$ を掛ける方向:
$A^f = h_{t-1} \cdot W_h^f + x_t \cdot W_x^f + b$ の形なので $W_h^f$ の勾配は $h_{t-1}^\top$ を左から掛ます。
$\frac{\partial L}{\partial W_h^f}$
上述の微分を連鎖律で繋げて $\frac{\partial L}{\partial W_h^f}$ を求めます。
\[\frac{\partial L}{\partial W_h^f} = \frac{\partial L}{\partial c_t} \odot \frac{\partial c_t}{\partial f} \odot \frac{\partial f}{\partial A^f} \odot \frac{\partial A^f}{\partial W_h^f}\]$\frac{\partial L}{\partial c_{t-1}} = \frac{\partial L}{\partial c_t} \odot \frac{\partial c_t}{\partial c_{t-1}} = ds \odot f$
$\frac{\partial L}{\partial W_h^f}$ の算出には使用しません。
$\frac{\partial c_t}{\partial c_{t-1}}$ を求めるために $f \odot c_{t−1} + g \odot i$ を $c_{t-1}$ で微分します。
\[\frac{\partial c_t}{\partial c_{t-1}} = f\]$\frac{\partial A^f}{\partial h_{t-1}}$, $\frac{\partial A^i}{\partial h_{t-1}}$, $\frac{\partial A^g}{\partial h_{t-1}}$, $\frac{\partial A^o}{\partial h_{t-1}}$
$\frac{\partial L}{\partial W_h^f}$ の算出には使用しません。
\(A^f = h_{t-1} \cdot W_h^f + x_t \cdot W_x^f + b \\ A^i = h_{t-1} \cdot W_h^i + x_t \cdot W_x^i + b \\ A^g = h_{t-1} \cdot W_h^g + x_t \cdot W_x^g + b \\ A^o = h_{t-1} \cdot W_h^o + x_t \cdot W_x^o + b\) 微分係数を求めます。
\[\frac{\partial A^f}{\partial h_{t-1}} = W_h^f \\ \frac{\partial A^i}{\partial h_{t-1}} = W_h^i \\ \frac{\partial A^g}{\partial h_{t-1}} = W_h^g \\ \frac{\partial A^o}{\partial h_{t-1}} = W_h^o\]$\frac{\partial L}{\partial h_{t-1}}$ の逆伝播
経路
$h_{t-1}$ は $f$・$i$・$g$・$o$ の 4 つすべてに影響するためそれぞれの経路の勾配を足し合わせます。
\[L \rightarrow c_t \rightarrow \{f, i, g\} \rightarrow A^{\{f,i,g\}} \rightarrow h_{t-1} \quad \text{※} \ c_t = f \odot c_{t-1} + g \odot i \ \text{より} \\ L \rightarrow h_t \rightarrow o \rightarrow A^o \rightarrow h_{t-1} \quad \text{※} \ h_t = o \odot \tanh(c_t) \ \text{より} \\\]$$1$ の勾配
連鎖律の繋ぎ方(各因子の関係を示す)はすべて $\odot$ で表します。
| ゲート | 連鎖律 | $da$ の値 |
|---|---|---|
| $dA^f$ | $dc_t \odot \frac{\partial c_t}{\partial f} \odot \frac{\partial f}{\partial A^f}$ | $dc_t \odot c_{t-1} \odot f \odot (1-f)$ |
| $dA^i$ | $dc_t \odot \frac{\partial c_t}{\partial i} \odot \frac{\partial i}{\partial A^i}$ | $dc_t \odot g \odot i \odot (1-i)$ |
| $dA^g$ | $dc_t \odot \frac{\partial c_t}{\partial g} \odot \frac{\partial g}{\partial A^g}$ | $dc_t \odot i \odot (1-g^2)$ |
| $dA^o$ | $dh_t \odot \frac{\partial h_t}{\partial o} \odot \frac{\partial o}{\partial A^o}$ | $dh_t \odot \tanh(c_t) \odot o \odot (1-o)$ |
$\frac{\partial L}{\partial h_{t-1}}$ の計算
Step 1. $dA$ を求める
4 つのゲートの勾配を横に連結します。
\[dA = \left[ dA^f \mid dA^i \mid dA^g \mid dA^o \right] \quad \text{shape: } (N, 4H)\]Step 2. $\frac{\partial L}{\partial h_{t-1}}$ を求める(最終的な勾配)
実際の計算( shape を意識した最終形)は $dA$ で一括で求められます。
\[\frac{\partial L}{\partial h_{t-1}} = dA \cdot W_h^\top\]$dA$ の中に 4 ゲートの寄与がすべて含まれているため、行列積 1 回で $f$・$i$・$g$・$o$ それぞれの $h_{t-1}$ への寄与が自動的に足し合わされます。
補足:$\frac{\partial L}{\partial W_h^f}$ との対比
$W_h^f$ と $h_{t-1}$ はどちらも $A^f = h_{t-1} \cdot W_h^f$ から来ています。
| 勾配 | 実際の計算 |
|---|---|
| $\frac{\partial L}{\partial W_h^f}$ | $h_{t-1}^\top \cdot dA^f$($h_{t-1}^\top$ を左からドット積) |
| $\frac{\partial L}{\partial h_{t-1}}$ | $dA \cdot W_h^\top$($W_h^\top$ を右からドット積) |
活性化関数
ハイパボリックタンジェント/双曲線正接( tanh function )
\[tanh(x) = \frac{e^x-e^{-x}}{e^{x} + e^{-x}}\]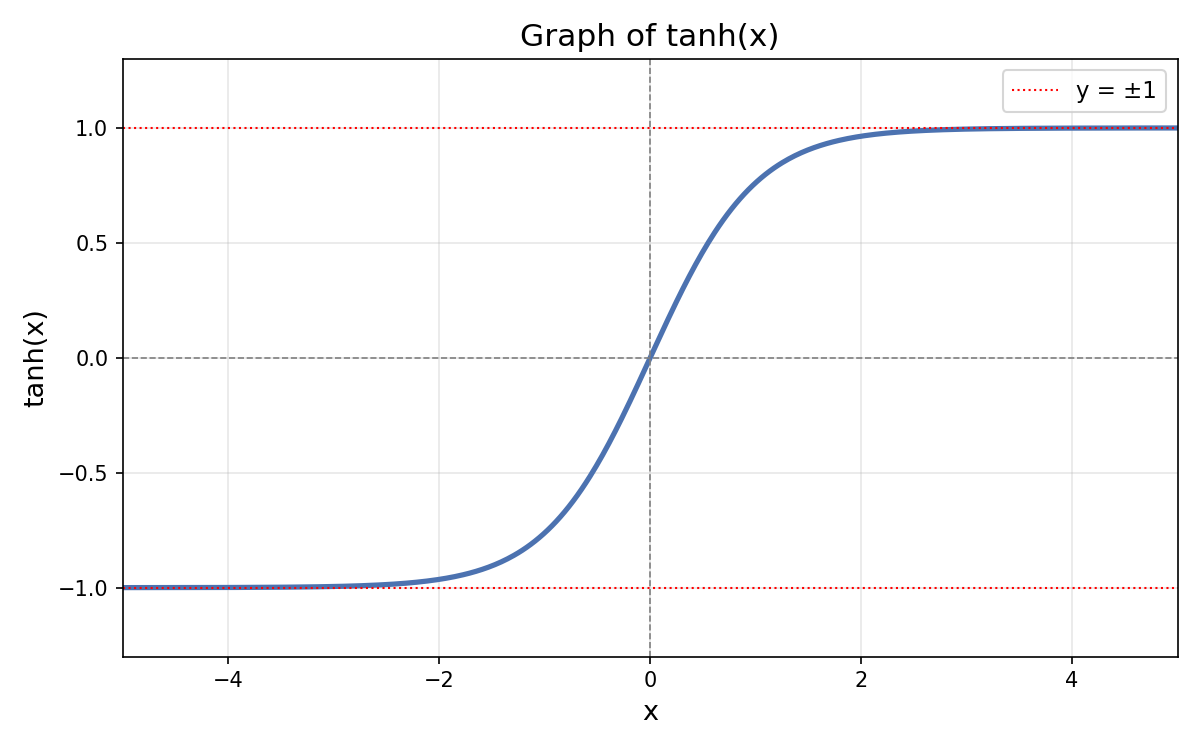
- tanh 関数の出力範囲は ( −1, 1 )で Sigmoid 関数( 0 - 1 )と異なり負の値を取れるため出力の平均がゼロに近く(zero-centered)なり次の層への入力が偏りにくく学習が安定しやすい
-
最大勾配が 1( x=0 付近)で Sigmoid 関数の最大勾配 0.25 の 4 倍で勾配消失が起きにくい(ただし、 x が大きくなると勾配はほぼ 0 になるため深いネットワークでは依然として勾配消失問題が発生する) - ReLU は勾配消失がさらに起きにくい
上記の勾配の性質より現在の深いネットワークの Affine レイヤの活性化関数は ReLU が主流だが RNN 、LSTM の内部ゲートの活性化関数には tanh を使用する場合が多い。
LeLU 関数
勾配消失
$x > 0$ のとき x( $x \le 0$ のとき 0 )なので勾配消失を抑えることができます。
補足
LSTM が勾配消失に強い理由
1. RNN の問題:勾配消失
RNN の逆伝播では dh_prev を求めるたびに $W_h^\top$ を掛け続ける。
これが $T$ ステップ分繰り返されるので、遠くのステップに勾配が届かない(消失する)。
2. LSTM のセル状態 $c$ による解決
LSTM はセル状態 $c$ を足し算で更新する。
\[c_t = f \odot c_{t-1} + g \odot i\]足し算の逆伝播は「上流の勾配をそのまま流す」ため、$c$ の経路では勾配が減衰しにくい。
dc_prev の逆伝播
dc_prev = ds * f
$T$ ステップ繰り返すと:
\[\frac{\partial L}{\partial c_0} = \frac{\partial L}{\partial c_T} \odot f_T \odot f_{T-1} \odot \cdots \odot f_1\]- 掛けるのは固定の $W_h^\top$ ではなく、各ステップで異なる $f$(forget gate)
- $f \approx 1$ に学習することで勾配をほぼそのまま流せる
- 「覚えておくべき情報がある」とき、ネットワークは $f \approx 1$ を出力するよう学習する
3. 「dWh は消失しないのか?」という疑問
LSTM でも dWh の計算自体は RNN と同じ。
dWh = np.dot(h_prev.T, dA)
遠くのステップからの勾配は dWh の経路では届きにくい。
ただし dc_prev の経路を通って遠くの情報が dA に届き、dWh に反映される。
| 経路 | 遠距離の勾配 | 役割 |
|---|---|---|
dh_prev(RNN と同じ) |
消失しやすい | 短期の依存関係を学習 |
dc_prev(LSTM 固有) |
消失しにくい | 長期の依存関係を学習 |
4. 役割分担まとめ
| 経路 | 何を学習するか |
|---|---|
dWh / dWx |
直近の文脈(短期依存) |
dc_prev |
遠く離れたステップの情報(長期依存) |
具体例
「彼女は日本人だ。だから彼女の母国語は__だ。」
- 「母国語」の直前の文脈(短期)→
dWh/dWxの経路 - 遠く離れた「日本人」という情報(長期)→
dc_prevの経路でセル $c$ に保持
両方の経路があることで、RNN では難しかった長距離依存を学習できる。
5. RNN vs LSTM まとめ
| 長距離の勾配経路 | 結果 | |
|---|---|---|
| RNN | dh_prev のみ($W_h^\top$ を $T$ 回掛ける) |
遠くのステップに勾配が届かない |
| LSTM | dc_prev がある($f$ を掛けるだけ) |
遠くのステップにも勾配が届く |
違いの本質:遠くから勾配を届ける経路があるかどうか。
シグモイド関数( Sigmoid function )
\[y = \frac{1}{1 + \exp(-x)}\]
シグモイド関数の定義は以下のとおり。 特徴は定義域 $-\infty$ <= x <= $\infty$ に対して y は 0 < y < 1 で $x = 0 のとき y = 0.5$
Python コード
def sigmoid(x):
return 1 / (1 + np.exp(-x))
勾配消失問題
| x の値 | sigmoid(x) |
|---|---|
| 0 | 0.25(最大) |
| ±1 | ≈ 0.05 |
| ±3 | ≈ 0.004 |
層が深くなるほど勾配が 0 に収束して学習が止まります。
補足 Affine 変換
Affine 変換
数学的には「線形変換+平行移動」のことで、Deep Learning では全結合層の計算を指します。
\[A = x W_x + h_{prev} W_h + b\]用語の対応
| 文脈 | 用語 | 例 |
|---|---|---|
| ゼロつく・教育系 | Affine 変換 | class Affine としてレイヤー実装 |
| PyTorch 公式 | Linear 変換 | nn.Linear |
| 論文・一般 | 全結合 / FC (Fully Connected) | FC layer |
どれも同じ計算 $xW + b$ を指します。
[!NOTE] ゼロつくでは Affine 変換後にスライス → 活性化関数という流れで LSTM を実装します。 4ゲート分を1つの大行列でまとめて計算することで、行列積を1回で済ませられます(効率化)。